Forschungs-Blog: So funktioniert maschinelle Übersetzung für Rätoromanisch

Angela Heldstab, Forschungsassistentin am Institut für Computerlinguistik der Universität Zürich
Das erste Modell, das zwischen Deutsch und allen rätoromanischen Idiomen übersetzen kann, ist online: alas.liarumantscha.ch. In diesem Blogpost erfahren Sie, wie wir bei unserem Projekt in Zusammenarbeit mit der Lia Rumantscha zum Trainieren eines maschinellen Übersetzungssystems gearbeitet haben: Wie funktioniert dieses System genau (nein, es ist kein LLM 😉), welche Daten – und woher – haben wir genutzt, wie haben wir Muttersprachler:innen involviert, und zu guter Letzt: Wie gut ist das System wirklich?
Wie funktioniert das denn?
Das besprochene System ist kein LLM, sondern ein «klassisches» neuronales Übersetzungssystem. Das bedeutet, dass es im Gegensatz zu einem LLM nicht dafür trainiert wurde, Fragen zu beantworten und Instruktionen zu befolgen. Stattdessen wurde es einzig und allein dafür trainiert, Sätze von der Quellsprache in die Zielsprache zu übertragen. Diese Spezialisierung erlaubt uns, die Grösse des Modells gering zu halten – es sind 100-mal weniger Parameter als bei einem LLM.
Dafür genutzt haben wir ein vortrainiertes Modell, das spezifisch dafür entwickelt wurde, möglichst viele Sprachen zu übersetzen: NLLB, «No Language Left Behind». Wir haben es um Rumantsch erweitert, indem wir es zusätzlich auf Daten der verschiedenen Varietäten trainiert haben.
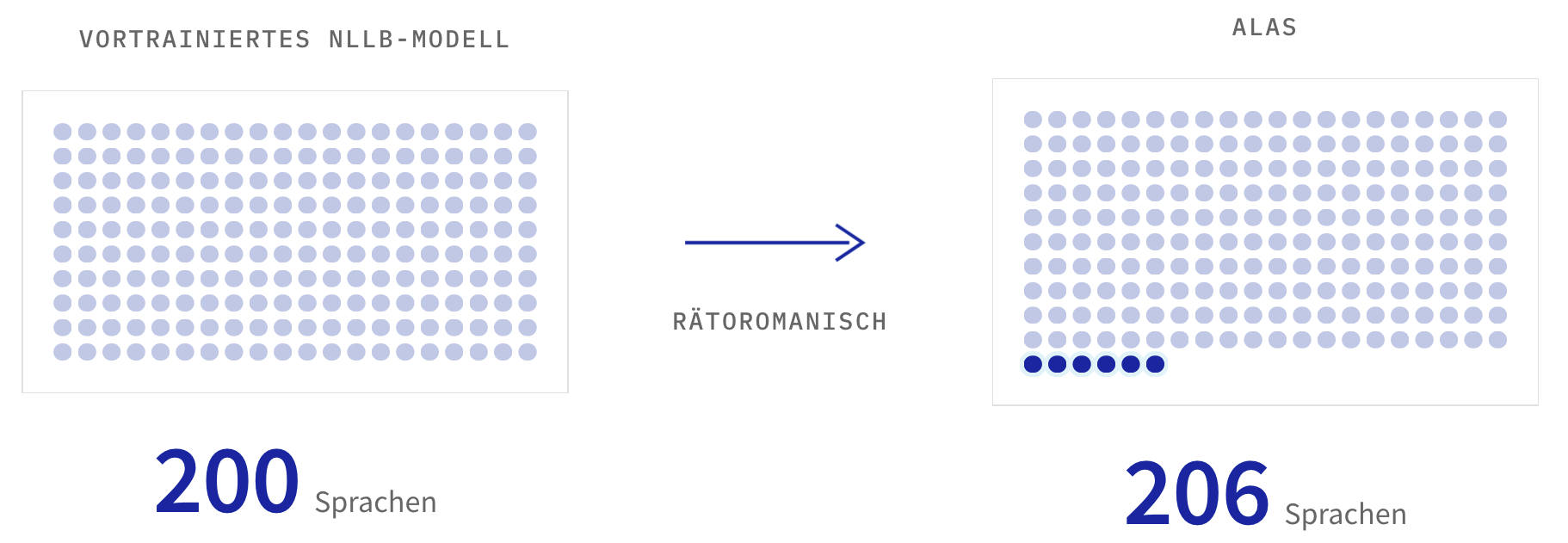
Die Daten, die in dieses Training eingeflossen sind, sind relativ übersichtlich: 250 Millionen Wörter auf Deutsch oder Rätoromanisch. Das sind weniger als 0,1% der ursprünglichen Trainingsdaten von NLLB und 0,01 % der Daten, die typischerweise in ein LLM einfliessen.
Woher kommen die Daten?
Rätoromanische Varietäten zählen mit Sicherheit zu sogenannten «Low-Resource-Languages», also Sprachen mit geringen «Ressourcen». In diesem Fall – jenem der textuellen maschinellen Übersetzung – bedeutet das, dass nur wenig parallele Datensätze vorhanden sind. Bei maschinellem Lernen und solchen Modellen benötigen wir Unmengen an Datensätzen, die auch maschinell lesbar sind. Rumantsch Grischun hat hier mit Sicherheit am meisten, gefolgt von Sursilvan. Die vorhandenen Datensätze der Idiome entsprechen im Verhältnis in etwa der Anzahl Menschen, die diese Idiome sprechen.
Wie konnten wir also ausreichend Datensätze sammeln, um ein solches Modell zu trainieren?
Dankenswerterweise gibt es eine Zahl von parallelen Datensätzen für Rätoromanisch. Dazu gehören 291 Schulbücher der Mediomatix-Reihe, welche in den verschiedenen Idiomen vorliegen, Gesetzestexte von Bund und Kanton, sowie interne parallele Daten, die in der Vergangenheit von RTR erstellt wurden.
Neben den parallelen Datensätzen – die in der maschinellen Übersetzung traditionell gesammelt werden – haben wir auch monolinguale Datensätze gesammelt, also textuelle Daten, welche nur auf einem bestimmten rätoromanischen Idiom vorhanden sind.
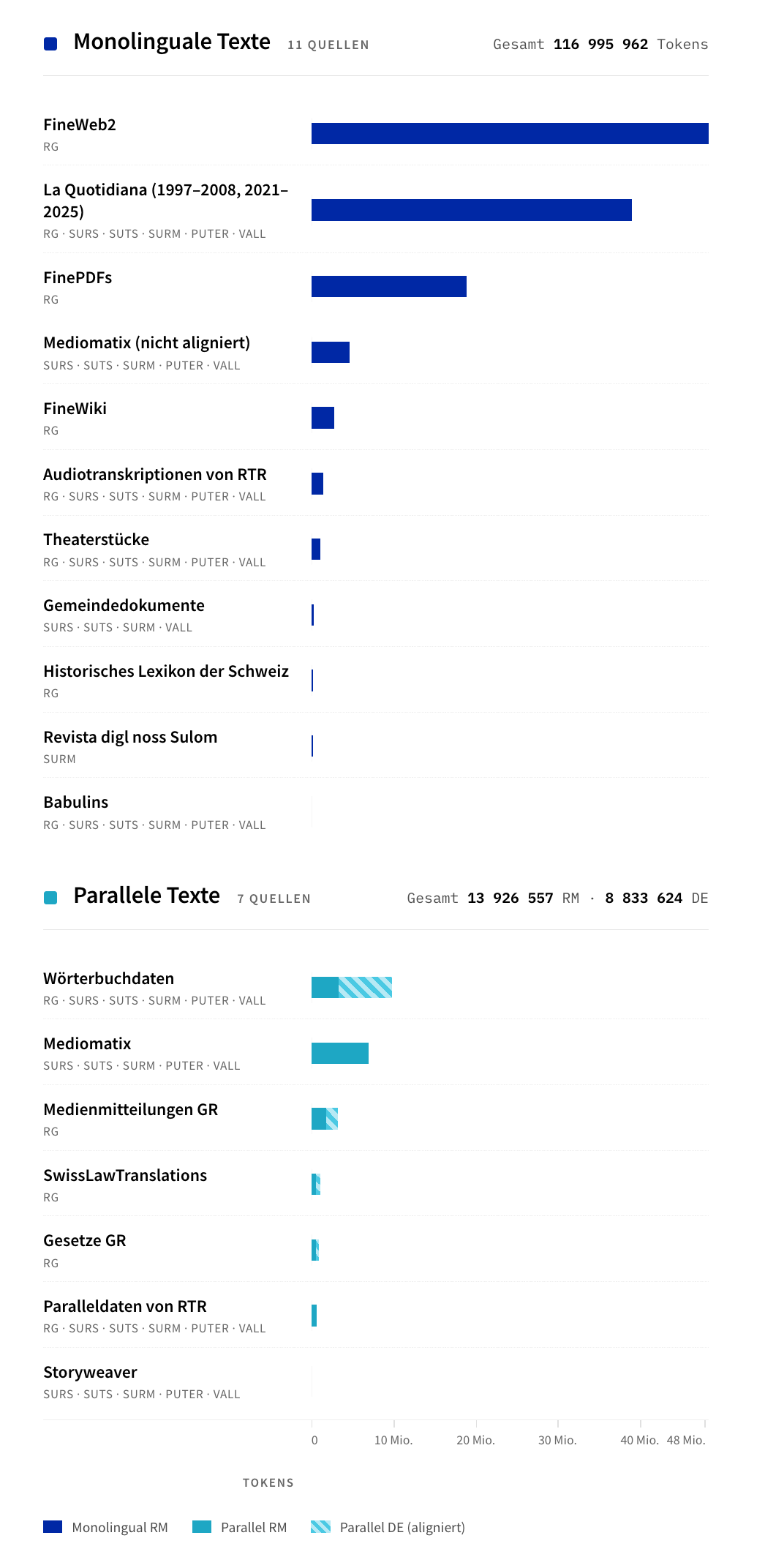
Um die monolingualen Datensätze parallel zu machen, haben wir sogenannte «Backtranslation» genutzt. Dabei geht es darum, ein bereits bestehendes maschinelles Übersetzungssystem zu nutzen, um mehr Daten zu generieren. Wir liessen also Gemini 2.5 Flash, also ein LLM, die monolingualen Datensätze auf den verschiedenen Idiomen auf Deutsch übersetzen.
Es ist bereits weithin anerkannt, dass LLMs bessere Übersetzungen liefern, wenn die ressourcenarme Sprache als Quellsprache verwendet wird und die ressourcenreiche Sprache die Zielsprache darstellt. Dies wurde in aktuellen Experimenten im letzten Jahr auch für rätoromanische Varietäten festgestellt. Das heisst, LLMs übersetzen besser von Rätoromanisch nach Deutsch als von Deutsch nach Rätoromanisch. Intuitiv ergibt das auch Sinn: Auch bei Menschen aus der Deutschschweiz ist es manchmal so, dass sie Rätoromanisch zwar nicht aktiv beherrschen, aber vielleicht durchs Französische oder Italienische gewisse Stellen passiv verstehen können.
So übersetzte Gemini 2.5 Flash die rätoromanischen Texte auch relativ gut auf Deutsch, und wir konnten somit hochqualitative Datensätze der rätoromanischen Idiome mit LLM-generierten Versionen auf Deutsch in einen parallelen Datensatz integrieren.
Sind die Übersetzungen gut?
Um das zu evaluieren, haben wir mit der Lia Rumantscha Evaluator:innen rekrutiert, welche in ihrem jeweiligen Idiom die Übersetzungen bewertet haben.
Für die Evaluation haben wir drei verschiedene Sammlungen von Übersetzungen genutzt: unsere eigene, maschinell erstellte; eine Referenzübersetzung, die uns von der Lia Rumantscha zur Verfügung gestellt wurde; sowie eine Übersetzung, die wir von Gemini Pro erstellen lassen haben. Die Evaluator:innen sahen jeweils zwei Übersetzungen, die sie vergleichen und bewerten sollten, ohne zu wissen, welche Übersetzung menschlich und welche maschinell, ob von uns oder Gemini, war. So konnten indirekte Vorurteile, die zu einer Über- oder Unterbewertung eines maschinellen Systems führen könnten, möglichst minimiert werden. (Diese Tendenz ist wohlbekannt, weshalb solche «blinde Evaluationen» in der Computerlinguistik üblich sind.)
Dabei gab es zwei Durchgänge: «Fluency» und «Accuracy», Flüssigkeit und Genauigkeit. Bei der Flüssigkeit geht es darum, wie gut der übersetzte Text klingt, ohne dass der Originaltext wichtig ist. Klingt die Übersetzung natürlich? Ist sie grammatikalisch richtig (zählt natürlich auch zur «Natürlichkeit»), und, besonders wichtig: Ist es das richtige Idiom? Unsere Evaluator:innen wurden gebeten, Texte oder Abschnitte, die zwar flüssig, aber ins falsche Idiom übersetzt wurden, schlicht und ergreifend als «falsch» bzw. nicht flüssig zu behandeln.
Bei der Runde zur Genauigkeit mussten unsere Evaluator:innen den Originaltext hinzuziehen. Hier ging es darum zu evaluieren, ob der Inhalt des übersetzten Textes auch wirklich übereinstimmt mit dem Inhalt des Originaltextes: Wurden Informationen weggelassen oder zugedichtet, entspricht ein Wort oder ein Ausdruck in der Übersetzung nicht der Bedeutung im Kontext des Originaltexts? Dazu mussten die Evaluator:innen die beiden Texte genau vergleichen.
In jeder Runde erhielten Evaluator:innen jeweils zwei Übersetzungen ins Rätoromanische, bei welchen sie nicht wussten, ob es die menschliche oder eine der beiden maschinellen war.
Grund für die zwei Runden war das Feedback aus einer Testrunde, in der wir hörten, dass es kognitiv anspruchsvoll sei, gleichzeitig auf beide Aspekte zu achten. Alle Evaluator:innen erhielten auch noch ein Dokument mit Richtlinien, an denen sie sich für Spezialfälle in etwa orientieren konnten; das meiste blieb aber im Ermessen der Evaluator:innen.
Dankenswerterweise fanden wir für alle Idiome mehrere Personen, welche evaluierten; sodass wir in der Regel einen Vergleichswert zwischen verschiedenen Menschen haben.
Im Durchschnitt über alle sechs Varietäten ergab sich folgendes Bild:
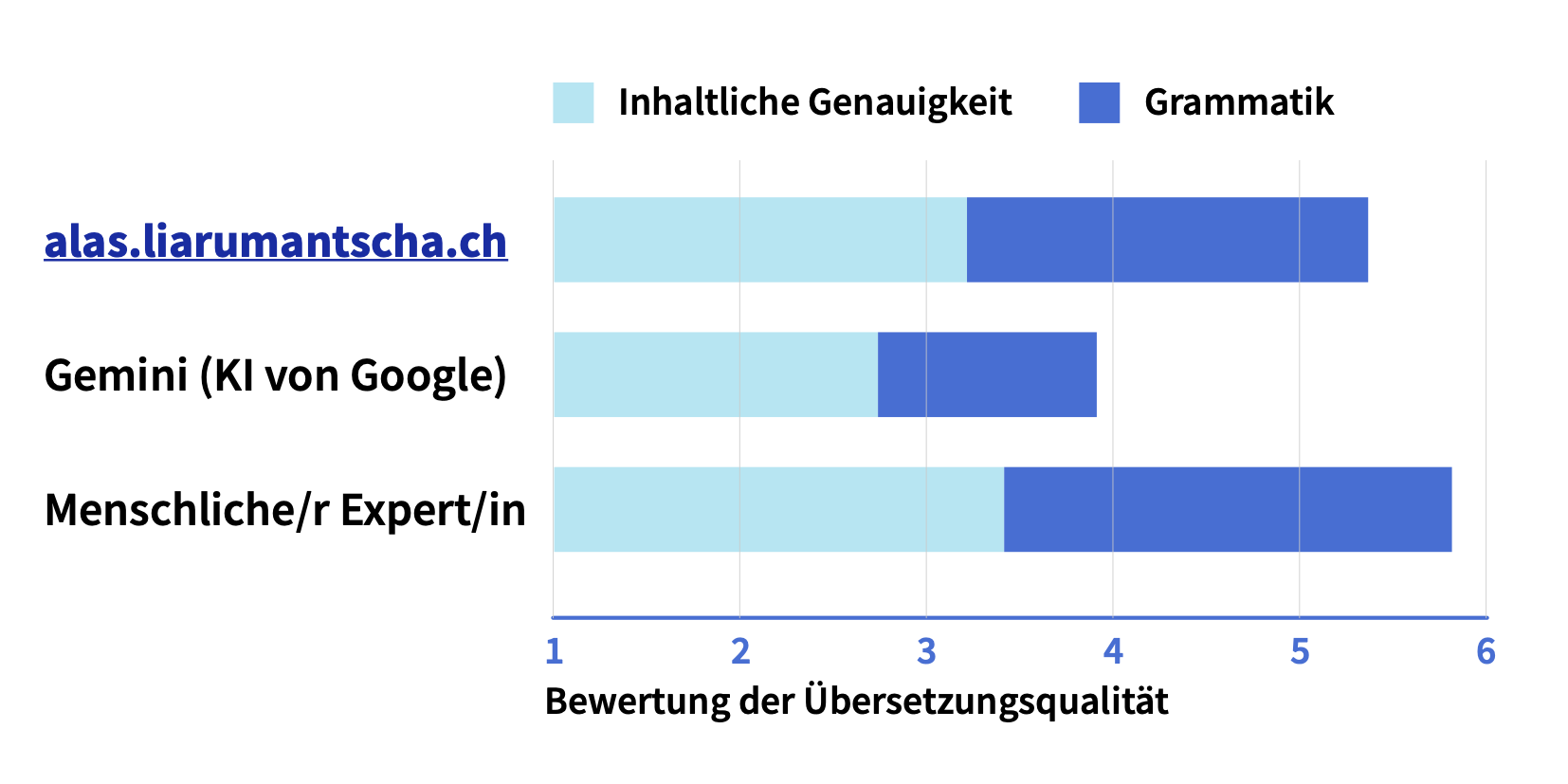
In Schulnoten ausgedrückt, könnte man das Ergebnis dieser Evaluierung demnach wie folgt zusammenfassen: Gemini erreicht eine Note von ca. 4 und es mangelt vor allem an der korrekten, grammatisch korrekten Wiedergabe der einzelnen Idiome. Alas erreicht ungefähr die Note 5¼ und kommt damit näher an die menschlichen Sprachprofis heran als Gemini.
Insgesamt können wir sagen: Das Modell ist parat, es funktioniert gut, und es ist jetzt auch für die interessierte Öffentlichkeit verfügbar. In dem Sinne: Viel Spass beim Ausprobieren!
Weitere Detailinformationen (wissenschaftliche Publikationen und Medienspiegel) sind auf unserer Projektseite verfügbar.