THIS PAGE IS NOT BEING UPDATED ANYMORE
Current project
Since April 2019, I am working on my mobility project From parallel corpora to multilingual exercises - Making use of large text collections and crowdsourcing techniques for innovative autonomous language learning applications funded by the SNF, partly at Språkbanken in Gothenburg and partly at GR@ELin Barcelona.
Short bio
I studied Computational Linguistics at the IMS in Stuttgart. During my studies I spent two years in Barcelona where I had the opportunity to participate in the PATExpert project at the TALN group and, later on, write my diploma thesis about dialogue interaction in role-playing video games.
Following my graduation, I led the development of digital cinema content logistics in an international firm (now Ymagis), resuming work that I had carried out for several years as student. From 2013 to 2017, I worked as PhD student in the SPARCLING project, investigating methods for assembling and querying large multiparallel corpora with a special focus on multilingual alignment.
Having learned programming in high school, I used to write small applications to support my own language acquisition (vocabulary and inflection) and later on continued developing language learning software with schoolmates, which brought us several prizes in the Jugend forscht competition. In 2017, I spent two months at Språkbanken in Gothenburg to learn about their approaches to corpus-based language learning applications.
Teaching and supervision
Starting in fall semester 2014 (HS14), I have been giving the last lecture in the programming techniques for computational linguistics series (PCL III), in HS15 together with Peter Makarov and in HS16 with Fabio Rinaldi. This lecture is centered around designing and implementing interactive applications (in contrast to processing pipelines) with complex data structures. Another key aspect of the lecture is software development in teams employing version control.
In spring semester 2014 (FS14), Martin Volk and I held a research seminar about methods and tools for large parallel corpora.
I (co-)supervised and worked with these students:
- Stéphanie Lehner (2014) – Deutsche Substantivkomposita in parallelen Korpora: Erstellung und Evaluation eines multilingualen Goldstandards zur Optimierung der automatischen Übersetzungsbestimmung (Lizentiatsarbeit ≈ master thesis) [thesis] [publication] [gold standard]
- Raphael Stöcklin (2015) – Implementation einer Mehrwortsuche in grossen parallelen Korpora anhand von Bilingwis (Facharbeit ≈ scientific project over at most six months)
- Phillip Ströbel (2017) – The “Raison d’Être” of Word Embeddings in Identifying Multiword Expressions in Bilingual Corpora (master thesis) [thesis]
- Selena Calleri & Barbara Pejkovic (2017) – Creation of a gold standard for hierarchical multilingual word alignment in six languages (English, French, German, Italian, Slovene, Spanish) [data]
- Dominique Sandoz (2017) – web frontend and middleware for Multilingwis2 (programming project) [publication] [git repo]
- Christopf Bless (contribution to the SPARCLING project as student assistant from 2016 to 2017):
- Youquery – web frontend for the exploration of corpus association measures [publication]
- SentStructure.js – D3.js-based library for visualizing annotation and alignment of corpus examples [git repo]
- HAT (hierarchical alignment tool) – tool for efficient multilingual hierarchical word and sentence alignment [git repo] [example1] [example2]
- Sarah Zurmühle (2018) – Erweiterung der Abfragesprache für das grosse multi-parallele Textkorpus des Multilingwis2 Projektes (bachelor thesis)
- Tannon Kew & Anastassia Shaitarova (2018–2019) – definition of a flexible corpus format for multiparallel corpora, conversion of existing corpora into that format and export to Multilingwis [publication] [web page]
- Jonathan Schaber (2019) – development of search interface for database in the DiFuPaRo research project
Interests
My main interest are parallel and multiparallel corpora, and their exploitation for multilingual phraseology and CALL applications. As regards the topic of language learning, I have mostly worked together with Gerold Schneider.
These applications require multiingual alignment on different levels, in particular alignment of units larger than single tokens (e.g. phrases), a problem I dealt with in my dissertation.
Other aspects include efficient corpus storage and query systems for multiparallel corpora and visualization of their results.
Other interests and proficiencies
I previously have been working for several years as SysAdmin for Linux servers and DevOp for applications based on PostgreSQL. During my time at the Department of Computational Linguistics, I had the chance to build our new IT infrastructure from scratch, based on virtualization (Proxmox) and distributed services. The architecture of our infrastructure has proven useful for both development and providing services, that is, web applications and pure web services. Most of my skills in this area date back to my active time at Selfnet e.V. in Stuttgart.
During my studies, I used to regularly take language courses. Besides German and English, I speak Spanish (C1), French, Portuguese, Italian (B1), Catalan and Swedish (A2). I also took lessons in Russian, Polish, Czech, Turkish and Icelandic, but, up to now, I can merely read simple texts in these languages.
I enjoy garlic (like in Tzatziki or Gazpacho), volleyball (my previous team) and good movies (Uni-Film Stuttgart, Filmstelle Zürich, Texas cinema). My preferred red wines come from the Montsant region.
Demos
(see also thumbnails on the right)
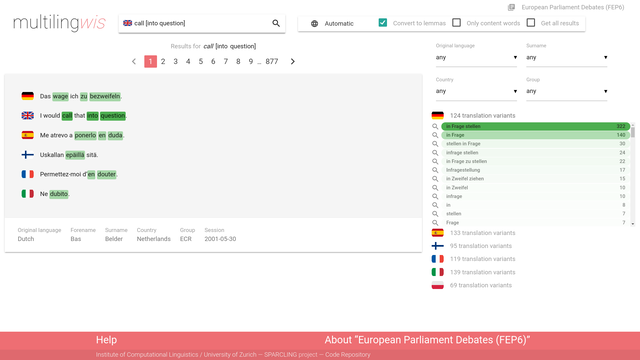
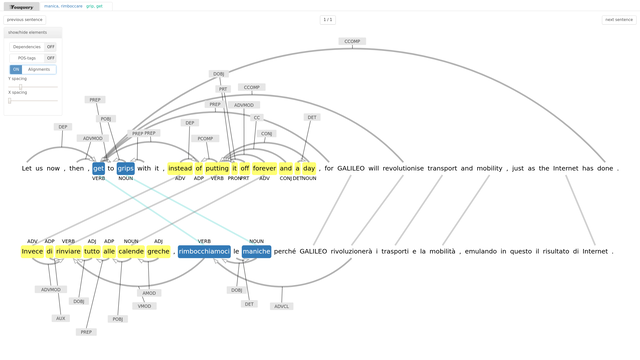
- Multilingwis2 – a web based search engine for exploration of word-aligned parallel and multiparallel corpora
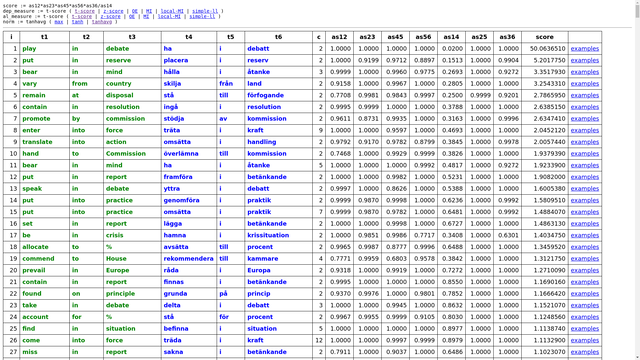
- Youquery – a web interface to explore properties of interlingual and intralingual corpus association measures
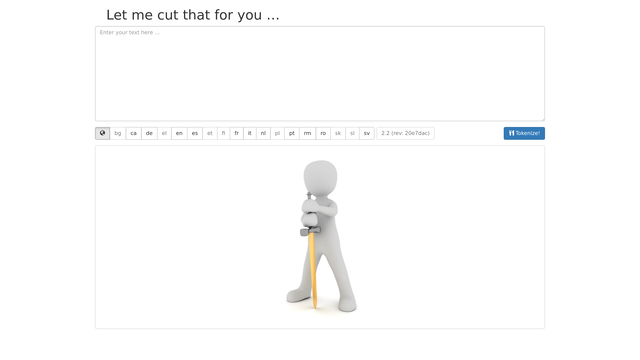
- Cutter – frontend for tokenization web service in several languages
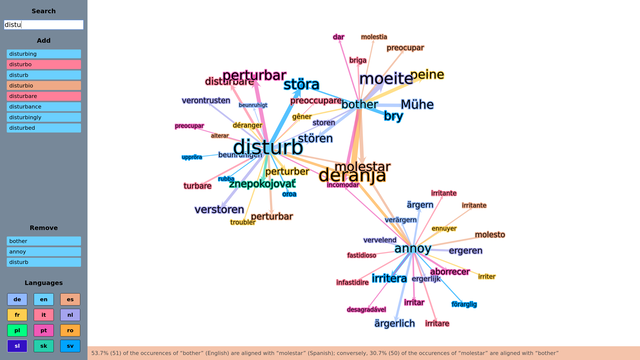
- Alignment Overlap – tool for exploring translations shared between multiple terms
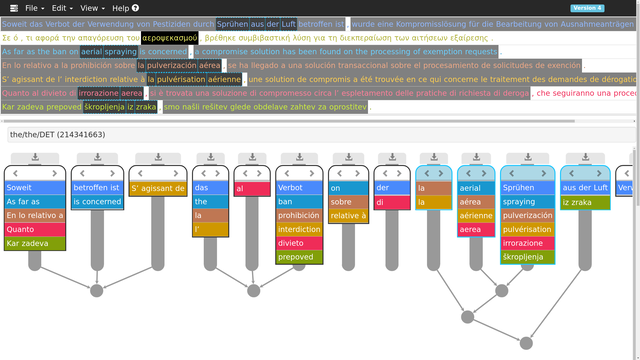
- Constellations – syntactic queries on word-aligned parallel corpora
Publications
ZORA Publikationsliste
Download-Optionen
Publikationen
-
LiRI Corpus Platform: Demonstration of a Web-Based Infrastructure for Multimodal Corpus Analysis Interspeech 2025, Rotterdam. https://www.isca-archive.org/interspeech_2025/vukovic25_interspeech.html
-
The LiRI Corpus Platform Linköping Electronic Conference Proceedings, 62–75. https://doi.org/10.3384/ecp210010
-
The LiRI Corpus Platform In K. Linden, J. Niemi, & T. Kontino (Eds.), CLARIN Annual Conference Proceedings (pp. 145–149). CLARIN ERIC. http://hdl.handle.net/10138/570996
-
Swissdox@ LiRI–a large database of media articles made accessible to researchers In K. Linden, J. Niemi, & T. Kontino (Eds.), CLARIN Annual Conference Proceedings (pp. 111–115). CLARIN ERIC. https://helda.helsinki.fi/bitstreams/6aa6e46b-697e-45da-b0f0-d5211d4e78bc/download#page=120
-
SwissBERT: The Multilingual Language Model for Switzerland Proceedings of the Swiss Text Analytics Conference, 54–69. https://aclanthology.org/2023.swisstext-1.6.pdf
-
Using a bilingual concordancer to promote metalinguistic reflection in the learning of an additional language: The case of B1 learners of Catalan In I. C. Santos Díaz, M. Torrado Cespón, J. M. Díaz Lage, & S. López Pérez (Eds.), Current Trends on Digital Technologies and Gaming for Teaching and Linguistics (pp. 27–45). Peter Lang. https://doi.org/10.3726/b20963
-
Learning languages from parallel corpora Slovenscina 2.0, 10, 101–131. https://doi.org/10.4312/slo2.0.2022.2.101-131
-
Binomials in Swedish corpora – ‘Ordpar 1965’ revisited In E. Volodina, D. Dannélls, A. Berdicevskis, M. Forsberg, & S. Virk (Eds.), Live and Learn : Festschrift in honor of Lars Borin (pp. 139–144). Department of Swedish, Multilingualism and Language Technology, University of Gothenburg.
-
Identifying phrasemes via interlingual association measures - A data-driven approach on dependency-parsed and word-aligned parallel corpora In C. Konecny, E. Autelli, A. Abel, & L. Zanasi (Eds.), Lexemkombinationen und typisierte Rede im mehrsprachigen Kontext (p. Epub ahead of print). Stauffenburg Verlag.
-
The DiFuPaRo database https://difuparo.linguistik.uzh.ch
-
Binomial adverbs in Germanic and Romance Languages : A corpus-based study. In J. Lavid-López, C. Maíz-Arévalo, & J. R. Zamorano-Mansilla (Eds.), Corpora in Translation and Contrastive Research in the Digital Age : Recent advances and explorations (pp. 326–342). John Benjamins. https://doi.org/10.1075/btl.158.13gra
-
Syntaktischer Atlas der deutschen Schweiz online https://dialektsyntax.linguistik.uzh.ch/
-
Using Multilingual Resources to Evaluate CEFRLex for Learner Applications 346–355. https://www.aclweb.org/anthology/2020.lrec-1.43.pdf
-
Modelling Large Parallel Corpora: The Zurich Parallel Corpus Collection (P. Bański, A. Barbaresi, H. Biber, E. Breiteneder, S. Clematide, M. Kupietz, H. Lüngen, & C. Iliadi, Eds.). Leibniz-Institut für Deutsche Sprache. https://doi.org/10.14618/ids-pub-9020
-
NLP Corpus Observatory – Looking for Constellations in Parallel Corpora to Improve Learners’ Collocational Skills 69–78. https://spraakbanken.gu.se/eng/icall/7th-nlp4call#prog
-
Cutter – a Universal Multilingual Tokenizer In M. Cieliebak, D. Tuggener, & F. Benites (Eds.), CEUR Workshop Proceedings (No. 2226; pp. 75–81). CEUR-WS. http://ceur-ws.org/Vol-2226/
-
A multilingual gold standard for translation spotting of German compounds and their corresponding multiword units in English, French, Italian and Spanish In R. Mitkov, J. Monti, G. Corpas Pastor, & V. Seretan (Eds.), Multiword Units in Machine Translation and Translation Technology (No. 341; pp. 125–145). John Benjamins. https://doi.org/10.1075/cilt.341
-
Exploiting alignment in multiparallel corpora for applications in linguistics and language learning (Dissertation, University of Zurich) https://doi.org/10.5167/uzh-153213
-
Multi-word Adverbs – How well are they handled in Parsing and Machine Translation? The 3rd Workshop on Multi-word Units in Machine Translation and Translation Technology (MUMTTT 2017), London.
-
Multilingwis2 – Explore Your Parallel Corpus Linköping Electronic Conference Proceedings, 247–250. http://www.ep.liu.se/ecp/article.asp?issue=131&article=031&volume=#
-
Exploring Properties of Intralingual and Interlingual Association Measures Visually Linköping Electronic Conference Proceedings, 314–317. http://www.ep.liu.se/ecp/article.asp?issue=131&article=045&volume=#
-
Crossing the Border Twice: Reimporting Prepositions to Alleviate L1-Specific Transfer Errors Linköping Electronic Conference Proceedings, 18–26. http://www.ep.liu.se/ecp/article.asp?issue=134&article=003
-
Bi-particle adverbs, PoS-tagging and the recognition of german separable prefix verbs KONVENS 2016, Bochum. https://www.linguistics.rub.de/konvens16/program/accepted.html
-
A Web Application for Geolocalized Signs in Synthesized Swiss German Sign Language Proceedings of the International Conference of Computers Helping People with Special Needs (ICCHP), Linz. https://doi.org/10.1007/978-3-319-41267-2_62
-
Efficient Exploration of Translation Variants in Large Multiparallel Corpora Using a Relational Database (P. Bański, M. Kupietz, H. Lüngen, A. Witt, A. Barbaresi, H. Biber, E. Breiteneder, & S. Clematide, Eds.; pp. 20–23). s.n. http://www.lrec-conf.org/proceedings/lrec2016/workshops/LREC2016Workshop-CMLC_Proceedings.pdf
-
Multilingwis – A Multilingual Search Tool for Multi-Word Units in Multiparallel Corpora In G. Corpas Pastor (Ed.), Computerised and Corpus-based Approaches to Phraseology: Monolingual and Multilingual Perspectives/Fraseología computacional y basada en corpus: perspectivas monolingües y multilingües (p. n/a). Tradulex.
-
Challenges in the alignment, management and exploitation of large and richly annotated multi-parallel corpora (P. Bański, H. Biber, E. Breiteneder, M. Kupietz, H. Lüngen, & A. Witt, Eds.; pp. 15–20). Institut für Deutsche Sprache. http://ids-pub.bsz-bw.de/files/3826/Graen_Clematide_Challenges_in_the_Alignment_management_and_exploitation_2015.pdf
-
Cleaning the Europarl Corpus for Linguistic Applications Konvens 2014, Hildesheim.
-
Innovations in parallel corpus search tools Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik. http://www.lrec-conf.org/proceedings/lrec2014/pdf/504_Paper.pdf