-

SwissADT pipeline
-

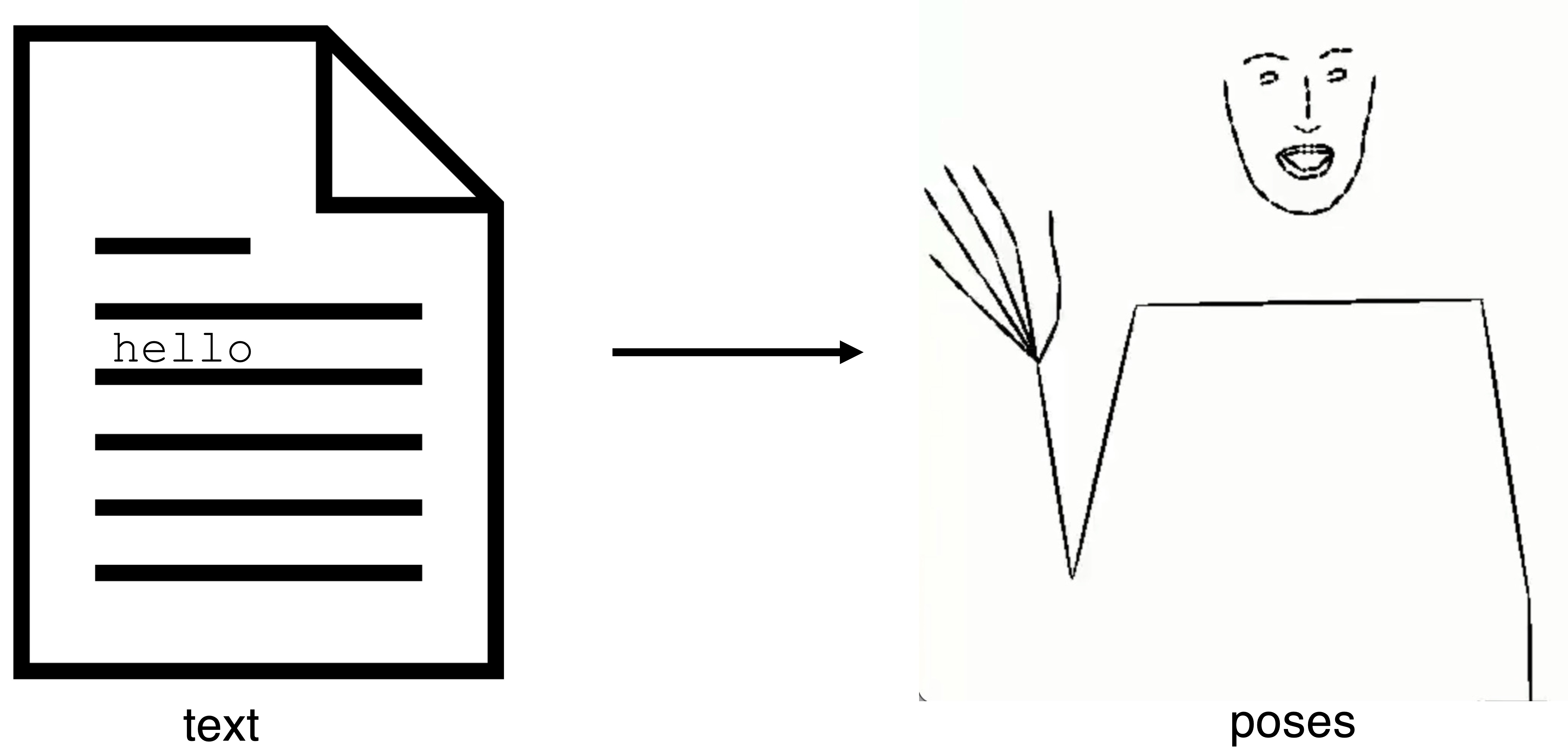
Evaluation of text-to-pose translation
-

Informed consent in sign language
-

Manual alignment of sign language videos and spoken language subtitles
-

Sign-to-text translation shared task
-

IICT subprojects
-

Comprehensibility of automatic text simplification output
-

SMILE I demonstrator
-

SMILE II data collection tasks
-

SMILE II studio @ UZH
-

SMILE II data processing
-

TEDxZurich talk Sarah Ebling
-

The essence of Sarah Ebling's TEDxZurich talk by Stefano Oberti
-

Video highlighting for automatic audio description translation
-
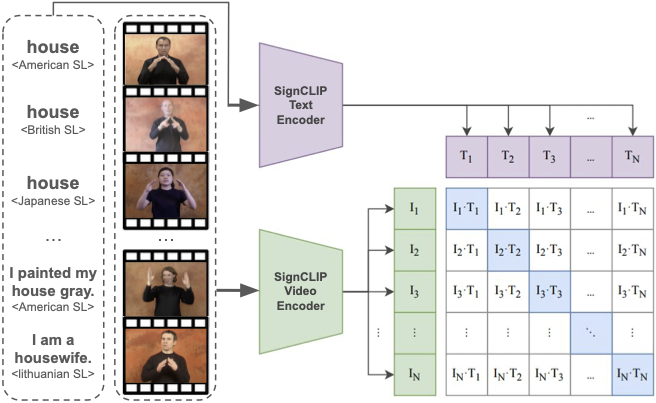
SignCLIP
-
SwissADT pipeline
-
Evaluation of text-to-pose translation
Language, Technology and Accessibility
Welcome to the webpage of our chair!

Our chair deals with language-based assistive technologies and digital accessibility. Our focus is on basic and application-oriented research.
We subscribe to a broad definition of language and communication, in line with the UN Convention on the Rights of Persons with Disabilities (UN CRPD); as such, we deal with spoken language (text and speech), sign language, simplified language, Braille, pictographs, etc.
We combine language and communication with technology and accessibility in two ways:
- We develop language-based technologies, most often relying on deep learning (artificial intelligence) approaches.
- We investigate the reception of these technologies among the users, e.g., through comprehension studies.
Our technologies focus on the contexts of hearing impairments, visual impairments, cognitive impairments, and language disorders.
The group is headed by Prof. Dr. Sarah Ebling.